
Code
import sys
from pathlib import Path
sys.path.append(str(Path.cwd()))In Part 2, we looked into some crucial sample pre-processing steps before modeling, establishing the required pipeline for data processing, evaluating various algorithms, and ultimately identifying an appropriate baseline model, that is CatBoost. As we proceed to Part 3, our focus will be on assessing the significance of features in the initial scraped dataset. We’ll achieve this by employing the feature_importances_ method of CatBoostRegressor and analyzing SHAP values. Additionally, we’ll systematically eliminate features showing lower importance or predictive capability. Excited to explore all these!
You can explore the project’s app on its website. For more details, visit the GitHub repository.
Check out the series for a deeper dive: - Part 1: Characterizing the Data - Part 2: Building a Baseline Model - Part 3: Feature Selection - Part 4: Feature Engineering - Part 5: Fine-Tuning
import sys
from pathlib import Path
sys.path.append(str(Path.cwd()))from pathlib import Path
import catboost
import numpy as np
import pandas as pd
import shap
from IPython.display import clear_output
from lets_plot import *
from lets_plot.mapping import as_discrete
from sklearn import metrics, model_selection
from tqdm import tqdm
from helper import utils
LetsPlot.setup_html()df = pd.read_parquet(
Path.cwd().joinpath("data").joinpath("2023-10-01_Processed_dataset_for_NB_use.gzip")
)Our initial step involves a train-test split. This process divides the data into two distinct sets: a training set and a testing set. The training set is employed for model training, while the testing set is exclusively reserved for model evaluation. This methodology allows models to be trained on the training set and then assessed for accuracy using the unseen testing set. Ultimately, this approach enables an unbiased evaluation of our model’s performance, utilizing the test set that remained untouched during the model training phase.
train, test = model_selection.train_test_split(
df, test_size=0.2, random_state=utils.Configuration.seed
)
print(f"Shape of train: {train.shape}")
print(f"Shape of test: {test.shape}")Shape of train: (2928, 50)
Shape of test: (732, 50)Next, we’ll apply a crucial step in our data preprocessing pipeline: transforming our target variable using a logarithmic function. Additionally, we’ll tackle missing values in our categorical features by replacing them with a designated label, “missing value.” This is needed, as CatBoost can handle missing values in numerical columns, but categorical missing values require manual attention to ensure accurate modeling.
processed_train = train.reset_index(drop=True).assign(
price=lambda df: np.log10(df.price)
) # Log transformation of 'price' column
# This step is needed since catboost cannot handle missing values when feature is categorical
for col in processed_train.columns:
if processed_train[col].dtype.name in ("bool", "object", "category"):
processed_train[col] = processed_train[col].fillna("missing value")
processed_train.shape(2928, 50)We will evaluate feature importance using two methods: the feature_importances_ attribute in CatBoost and SHAP values from the SHAP library. To begin examining feature importances, we’ll initiate model training. This involves further partitioning the training set, reserving a portion for CatBoost training (validation dataset). This allows us to stop the training process when overfitting emerges. Preventing overfitting is crucial, as it ensures we don’t work with an overly biased model. Additionally, if overfitting occurs, stopping training earlier helps conserve time and resources.
features = processed_train.columns[~processed_train.columns.str.contains("price")]
numerical_features = processed_train.select_dtypes("number").columns.to_list()
categorical_features = processed_train.select_dtypes("object").columns.to_list()
train_FS, validation_FS = model_selection.train_test_split(
processed_train, test_size=0.2, random_state=utils.Configuration.seed
)
# Get target variables
tr_y = train_FS[utils.Configuration.target_col]
val_y = validation_FS[utils.Configuration.target_col]
# Get feature matrices
tr_X = train_FS.loc[:, features]
val_X = validation_FS.loc[:, features]
print(f"Train dataset shape: {tr_X.shape} {tr_y.shape}")
print(f"Validation dataset shape: {val_X.shape} {val_y.shape}")Train dataset shape: (2342, 49) (2342,)
Validation dataset shape: (586, 49) (586,)train_dataset = catboost.Pool(tr_X, tr_y, cat_features=categorical_features)
validation_dataset = catboost.Pool(val_X, val_y, cat_features=categorical_features)As you can see below, the training loss steadily decreases, but the validation loss reaches a plateau. Thanks to the validation dataset, we can stop the training well before the initially set 2000 iterations. This early stopping is crucial for preventing overfitting and ensures a more balanced and effective model.
model = catboost.CatBoostRegressor(
iterations=2000,
random_seed=utils.Configuration.seed,
loss_function="RMSE",
)
model.fit(
train_dataset,
eval_set=[validation_dataset],
early_stopping_rounds=20,
use_best_model=True,
verbose=2000,
plot=False,
)Learning rate set to 0.038132
0: learn: 0.3187437 test: 0.3148628 best: 0.3148628 (0) total: 315ms remaining: 10m 28s
Stopped by overfitting detector (20 iterations wait)
bestTest = 0.1087393065
bestIteration = 850
Shrink model to first 851 iterations.<catboost.core.CatBoostRegressor at 0x1a3c8d76d10>According to our trained CatBoost model, the most significant feature in our dataset is the living_area, followed by cadastral_income and latitude. To validate and compare these findings, we’ll examine the SHAP values to understand how they align or differ from the feature importances provided by the model.
(
pd.concat(
[pd.Series(model.feature_names_), pd.Series(model.feature_importances_)], axis=1
)
.sort_values(by=1, ascending=False)
.rename(columns={0: "name", 1: "importance"})
.reset_index(drop=True)
.pipe(
lambda df: ggplot(df, aes("name", "importance"))
+ geom_bar(stat="identity")
+ labs(
title="Assessing Feature Importance",
subtitle=""" based on the feature_importances_ attribute
""",
x="",
y="Feature Importance",
)
+ theme(
plot_subtitle=element_text(
size=12, face="italic"
), # Customize subtitle appearance
plot_title=element_text(size=15, face="bold"), # Customize title appearance
)
+ ggsize(800, 600)
)
)SHAP (SHapley Additive exPlanations) values offer a method to understand the predictions made by any machine learning model. These values leverage a game-theoretic approach to quantify the contribution of each “player” (feature) to the final prediction. In the realm of machine learning, SHAP values assign an importance value to each feature, delineating its contribution to the model’s output.
SHAP values provide detailed insights into how each feature influences individual predictions, their relative significance in comparison to one another, and the model’s reliance on interactions between features. This comprehensive perspective enables a deeper understanding of the factors that drive the model’s decision-making process.
In this phase, our primary focus will involve computing SHAP values and then creating visualizations, such as bar plots and beeswarm plots, to illustrate feature importance and interactionss.
shap.initjs()
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(
catboost.Pool(tr_X, tr_y, cat_features=categorical_features)
)
The summary plot at Figure 2 provides a clear depiction of feature importance within the model. The outcomes reveal that “Living area,” “Surface of the plot,” and “Cadastral income” emerge as important factors in influencing the model’s predictions. These features prominently contribute to determining the model’s results.
shap.summary_plot(shap_values, tr_X, plot_type="bar", plot_size=[11, 5])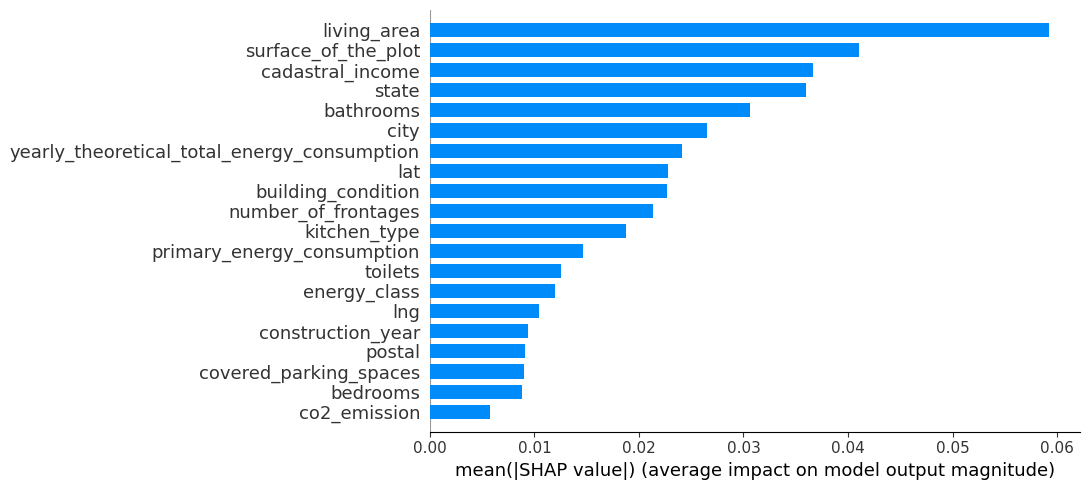
The beeswarm plot (Figure 3) can be best understood through the following breakdown:
Moreover: - Each point’s color on the plot signifies the respective feature’s value for that specific data point. Red indicates high values, while blue represents low values. - Every individual point on the plot corresponds to a particular row from the original dataset. Collectively, these points illustrate how different data points and their associated feature values contribute to the model’s predictions, especially concerning feature importance.
Upon examining the “living area” feature, you’ll notice it predominantly displays a high positive SHAP value. This suggests that a larger living area tends to have a positive effect on the output, which in this context is the price. Conversely, higher values of “primary energy consumption” are associated with a negative impact on the price, reflected by their negative SHAP values.
Consideration of the spread of SHAP values and their relation to predictive power is important. A wider spread or a denser distribution of data points implies greater variability or a more significant influence on the model’s predictions. This insight allows us to evaluate the significance of features regarding their contribution to the model’s overall output.
This context clarifies why “living area” holds greater importance compared to “CO2 emission.” The broader impact and higher variability of the “living area” feature in influencing the model’s predictions make it a more crucial determinant of the output, thus carrying more weight in the model’s decision-making process.rtance.
shap.summary_plot(shap_values, tr_X)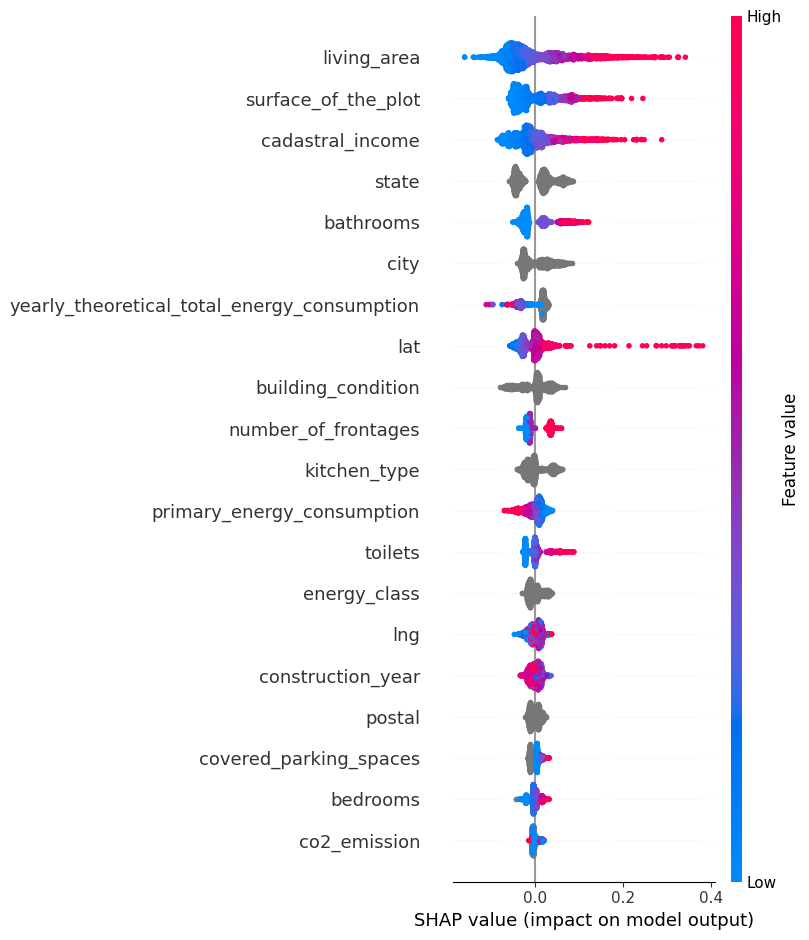
Let’s examine the ranking or order of feature importances derived from both Gini impurity and SHAP values to understand how they compare and whether they yield similar or differing insights. As you can see from the table below, they are fairly similar.
catboost_feature_importance = (
pd.concat(
[pd.Series(model.feature_names_), pd.Series(model.feature_importances_)], axis=1
)
.sort_values(by=1, ascending=False)
.rename(columns={0: "catboost_name", 1: "importance"})
.reset_index(drop=True)
)shap_feature_importance = (
pd.DataFrame(shap_values, columns=tr_X.columns)
.abs()
.mean()
.sort_values(ascending=False)
.reset_index()
.rename(columns={"index": "shap_name", 0: "shap"})
)pd.concat(
[
catboost_feature_importance.drop(columns="importance"),
shap_feature_importance.drop(columns="shap"),
],
axis=1,
)| catboost_name | shap_name | |
|---|---|---|
| 0 | living_area | living_area |
| 1 | cadastral_income | surface_of_the_plot |
| 2 | lat | cadastral_income |
| 3 | state | state |
| 4 | bathrooms | bathrooms |
| 5 | surface_of_the_plot | city |
| 6 | city | yearly_theoretical_total_energy_consumption |
| 7 | building_condition | lat |
| 8 | kitchen_type | building_condition |
| 9 | yearly_theoretical_total_energy_consumption | number_of_frontages |
| 10 | toilets | kitchen_type |
| 11 | number_of_frontages | primary_energy_consumption |
| 12 | lng | toilets |
| 13 | construction_year | energy_class |
| 14 | primary_energy_consumption | lng |
| 15 | energy_class | construction_year |
| 16 | bedrooms | postal |
| 17 | postal | covered_parking_spaces |
| 18 | covered_parking_spaces | bedrooms |
| 19 | outdoor_parking_spaces | co2_emission |
| 20 | surroundings_type | outdoor_parking_spaces |
| 21 | co2_emission | surroundings_type |
| 22 | living_room_surface | office |
| 23 | available_as_of | kitchen_surface |
| 24 | kitchen_surface | street |
| 25 | latest_land_use_designation | tv_cable |
| 26 | width_of_the_lot_on_the_street | living_room_surface |
| 27 | tv_cable | width_of_the_lot_on_the_street |
| 28 | office | gas_water__electricity |
| 29 | garden_surface | basement |
| 30 | bedroom_2_surface | latest_land_use_designation |
| 31 | bedroom_1_surface | bedroom_3_surface |
| 32 | bedroom_3_surface | bedroom_2_surface |
| 33 | street | tenement_building |
| 34 | tenement_building | garden_surface |
| 35 | heating_type | as_built_plan |
| 36 | gas_water__electricity | available_as_of |
| 37 | basement | subdivision_permit |
| 38 | subdivision_permit | bedroom_1_surface |
| 39 | double_glazing | heating_type |
| 40 | as_built_plan | connection_to_sewer_network |
| 41 | street_frontage_width | possible_priority_purchase_right |
| 42 | possible_priority_purchase_right | dining_room |
| 43 | connection_to_sewer_network | double_glazing |
| 44 | furnished | furnished |
| 45 | planning_permission_obtained | street_frontage_width |
| 46 | proceedings_for_breach_of_planning_regulations | proceedings_for_breach_of_planning_regulations |
| 47 | dining_room | planning_permission_obtained |
| 48 | flood_zone_type | flood_zone_type |
Next, we’ll work on the initial feature elimination process based on SHAP values using CatBoost’s select_features method. Although a rich set of features can be advantageous, the quest for model interpretability prompts us to consider the need for a streamlined feature set.
Our objective here is to remove features that have minimal impact on the final predictive output, retaining only the most influential ones. This action streamlines our model, enhancing its interpretability and making it easier to understand the factors driving its predictions.
regressor = catboost.CatBoostRegressor(
iterations=1000,
cat_features=categorical_features,
random_seed=utils.Configuration.seed,
loss_function="RMSE",
)
rfe_dict = regressor.select_features(
algorithm="RecursiveByShapValues",
shap_calc_type="Exact",
X=tr_X,
y=tr_y,
eval_set=(val_X, val_y),
features_for_select="0-48",
num_features_to_select=1,
steps=10,
verbose=2000,
train_final_model=False,
plot=False,
)Learning rate set to 0.0582
Step #1 out of 10
0: learn: 0.3152318 test: 0.3115119 best: 0.3115119 (0) total: 65.4ms remaining: 1m 5s
999: learn: 0.0474957 test: 0.1066737 best: 0.1065423 (961) total: 31.1s remaining: 0us
bestTest = 0.1065422651
bestIteration = 961
Shrink model to first 962 iterations.
Feature #38 eliminated
Feature #28 eliminated
Feature #20 eliminated
Feature #22 eliminated
Feature #19 eliminated
Feature #14 eliminated
Feature #11 eliminated
Feature #0 eliminated
Feature #31 eliminated
Feature #15 eliminated
Feature #30 eliminated
Feature #41 eliminated
Feature #33 eliminated
Feature #17 eliminated
Feature #45 eliminated
Feature #18 eliminated
Step #2 out of 10
0: learn: 0.3155660 test: 0.3112354 best: 0.3112354 (0) total: 22.5ms remaining: 22.5s
999: learn: 0.0505860 test: 0.1056381 best: 0.1056078 (984) total: 17.1s remaining: 0us
bestTest = 0.1056077628
bestIteration = 984
Shrink model to first 985 iterations.
Feature #39 eliminated
Feature #2 eliminated
Feature #21 eliminated
Feature #34 eliminated
Feature #4 eliminated
Feature #6 eliminated
Feature #1 eliminated
Feature #24 eliminated
Feature #9 eliminated
Feature #35 eliminated
Feature #5 eliminated
Step #3 out of 10
0: learn: 0.3150998 test: 0.3120655 best: 0.3120655 (0) total: 16.9ms remaining: 16.8s
999: learn: 0.0495254 test: 0.1058574 best: 0.1058574 (999) total: 18s remaining: 0us
bestTest = 0.1058574346
bestIteration = 999
Feature #26 eliminated
Feature #37 eliminated
Feature #29 eliminated
Feature #16 eliminated
Feature #12 eliminated
Feature #13 eliminated
Feature #7 eliminated
Step #4 out of 10
0: learn: 0.3142786 test: 0.3109611 best: 0.3109611 (0) total: 16.1ms remaining: 16.1s
999: learn: 0.0519507 test: 0.1108987 best: 0.1107855 (849) total: 14.1s remaining: 0us
bestTest = 0.1107855404
bestIteration = 849
Shrink model to first 850 iterations.
Feature #46 eliminated
Feature #23 eliminated
Feature #27 eliminated
Feature #40 eliminated
Feature #43 eliminated
Step #5 out of 10
0: learn: 0.3143922 test: 0.3107735 best: 0.3107735 (0) total: 16.1ms remaining: 16.1s
999: learn: 0.0542961 test: 0.1163795 best: 0.1163795 (999) total: 12.8s remaining: 0us
bestTest = 0.1163795207
bestIteration = 999
Feature #48 eliminated
Feature #32 eliminated
Feature #3 eliminated
Step #6 out of 10
0: learn: 0.3148243 test: 0.3111962 best: 0.3111962 (0) total: 12ms remaining: 12s
999: learn: 0.0674641 test: 0.1229819 best: 0.1225339 (626) total: 12s remaining: 0us
bestTest = 0.1225338768
bestIteration = 626
Shrink model to first 627 iterations.
Feature #42 eliminated
Feature #36 eliminated
Step #7 out of 10
0: learn: 0.3147967 test: 0.3113498 best: 0.3113498 (0) total: 16.6ms remaining: 16.5s
999: learn: 0.0856311 test: 0.1359971 best: 0.1341680 (459) total: 13.8s remaining: 0us
bestTest = 0.1341679745
bestIteration = 459
Shrink model to first 460 iterations.
Feature #8 eliminated
Feature #44 eliminated
Step #8 out of 10
0: learn: 0.3148282 test: 0.3113391 best: 0.3113391 (0) total: 3.57ms remaining: 3.57s
999: learn: 0.1023147 test: 0.1583956 best: 0.1531225 (197) total: 1.58s remaining: 0us
bestTest = 0.1531224776
bestIteration = 197
Shrink model to first 198 iterations.
Feature #47 eliminated
Step #9 out of 10
0: learn: 0.3155241 test: 0.3116638 best: 0.3116638 (0) total: 2.54ms remaining: 2.54s
999: learn: 0.1531420 test: 0.1895159 best: 0.1823469 (181) total: 1.5s remaining: 0us
bestTest = 0.1823469242
bestIteration = 181
Shrink model to first 182 iterations.
Feature #10 eliminated
Step #10 out of 10
0: learn: 0.3166921 test: 0.3133613 best: 0.3133613 (0) total: 1.63ms remaining: 1.63s
999: learn: 0.2051774 test: 0.2217136 best: 0.2164558 (240) total: 1.45s remaining: 0us
bestTest = 0.2164557771
bestIteration = 240
Shrink model to first 241 iterations.Through Recursive Feature Elimination, we’ve successfully decreased the number of features from an initial count of 49 to a more concise set of 17, up to and including the “bedrooms” feature. This reduction in features hasn’t notably affected our model’s performance, enabling us to retain a comparable level of predictive accuracy. This streamlined dataset enhances the model’s simplicity and interpretability without compromising its effectiveness.
features_to_keep = (
rfe_dict["eliminated_features_names"][33:] + rfe_dict["selected_features_names"]
)
print(features_to_keep)['bedrooms', 'state', 'kitchen_type', 'number_of_frontages', 'toilets', 'street', 'lng', 'primary_energy_consumption', 'bathrooms', 'yearly_theoretical_total_energy_consumption', 'surface_of_the_plot', 'building_condition', 'city', 'lat', 'cadastral_income', 'living_area']That’s it for now. In the next part, our focus will be on identifying potential outliers within our dataset. Additionally, we’ll dive into several further feature engineering steps aimed at increasing our model’s performance. For this, we will use cross-validation, ensuring the robustness and reliability of our modes. Looking forward to the next steps!